Manual Setup¶
Graylog server on Linux¶
Prerequisites¶
Graylog depends on MongoDB and Elasticsearch to operate, please refer to the system requirements for details.
Downloading and extracting the server¶
Download the tar archive from the download pages and extract it on your system:
~$ tar xvfz graylog-VERSION.tgz
~$ cd graylog-VERSION
Configuration¶
Now copy the example configuration file:
~# cp graylog.conf.example /etc/graylog/server/server.conf
You can leave most variables as they are for a first start. All of them should be well documented.
Configure at least the following variables in /etc/graylog/server/server.conf:
is_master = true
- Set only one
graylog-servernode as the master. This node will perform periodical and maintenance actions that slave nodes won’t. Every slave node will accept messages just as the master nodes. Nodes will fall back to slave mode if there already is a master in the cluster.
password_secret
- You must set a secret that is used for password encryption and salting here. The server will refuse to start if it’s not set. Generate a secret with for example
pwgen -N 1 -s 96. If you run multiplegraylog-servernodes, make sure you use the samepassword_secretfor all of them!
root_password_sha2
- A SHA2 hash of a password you will use for your initial login. Set this to a SHA2 hash generated with
echo -n yourpassword | shasum -a 256and you will be able to log in to the web interface with username admin and password yourpassword.
elasticsearch_shards = 4
- The number of shards for your indices. A good setting here highly depends on the number of nodes in your Elasticsearch cluster. If you have one node, set it to
1.
elasticsearch_replicas = 0
- The number of replicas for your indices. A good setting here highly depends on the number of nodes in your Elasticsearch cluster. If you have one node, set it to
0.
mongodb_uri
- Enter your MongoDB connection and authentication information here.
Starting the server¶
You need to have Java installed. Running the OpenJDK is totally fine and should be available on all platforms. For example on Debian it is:
~$ apt-get install openjdk-8-jre
Start the server:
~$ cd bin/
~$ ./graylogctl start
The server will try to write a node_id to the graylog-server-node-id file. It won’t start if it can’t write there because of for
example missing permissions.
See the startup parameters description below to learn more about available startup parameters. Note that you might have to be root to bind to the popular port 514 for syslog inputs.
You should see a line like this in the debug output of Graylog successfully connected to your Elasticsearch cluster:
2013-10-01 12:13:22,382 DEBUG: org.elasticsearch.transport.netty - [graylog-server] connected to node [[Unuscione, Angelo][thN_gIBkQDm2ab7k-2Zaaw][inet[/10.37.160.227:9300]]]
You can find the logs of Graylog in the directory logs/.
Important: All systems running Graylog must have synchronised system time. We strongly recommend to use NTP or similar mechanisms on all machines of your Graylog infrastructure.
Supplying external logging configuration¶
Graylog is using Apache Log4j 2 for its internal logging and ships with a default log configuration file which is embedded within the shipped JAR.
In case you need to modify Graylog’s logging configuration, you can supply a Java system property specifying the path to
the configuration file in your start script (e. g. graylogctl).
Append this before the -jar parameter:
-Dlog4j.configurationFile=file:///path/to/log4j2.xml
Substitute the actual path to the file for the /path/to/log4j2.xml in the example.
In case you do not have a log rotation system already in place, you can also configure Graylog to rotate logs based on their size to prevent the log files to grow without bounds using the RollingFileAppender.
One such example log4j2.xml configuration is shown below:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration packages="org.graylog2.log4j" shutdownHook="disable">
<Appenders>
<RollingFile name="RollingFile" fileName="/tmp/logs/graylog.log"
filePattern="/tmp/logs/graylog-%d{yyyy-MM-dd}.log.gz">
<PatternLayout>
<Pattern>%d %-5p: %c - %m%n</Pattern>
</PatternLayout>
<!-- Rotate logs every day or when the size exceeds 10 MB (whichever comes first) -->
<Policies>
<TimeBasedTriggeringPolicy modulate="true"/>
<SizeBasedTriggeringPolicy size="10 MB"/>
</Policies>
<!-- Keep a maximum of 10 log files -->
<DefaultRolloverStrategy max="10"/>
</RollingFile>
<Console name="STDOUT" target="SYSTEM_OUT">
<PatternLayout pattern="%d %-5p: %c - %m%n"/>
</Console>
<!-- Internal Graylog log appender. Please do not disable. This makes internal log messages available via REST calls. -->
<Memory name="graylog-internal-logs" bufferSize="500"/>
</Appenders>
<Loggers>
<Logger name="org.graylog2" level="info"/>
<Logger name="com.github.joschi.jadconfig" level="warn"/>
<Logger name="org.apache.directory.api.ldap.model.message.BindRequestImpl" level="error"/>
<Logger name="org.elasticsearch.script" level="warn"/>
<Logger name="org.graylog2.periodical.VersionCheckThread" level="off"/>
<Logger name="org.drools.compiler.kie.builder.impl.KieRepositoryImpl" level="warn"/>
<Logger name="com.joestelmach.natty.Parser" level="warn"/>
<Logger name="kafka.log.Log" level="warn"/>
<Logger name="kafka.log.OffsetIndex" level="warn"/>
<Logger name="org.apache.shiro.session.mgt.AbstractValidatingSessionManager" level="warn"/>
<Root level="warn">
<AppenderRef ref="STDOUT"/>
<AppenderRef ref="RollingFile"/>
<AppenderRef ref="graylog-internal-logs"/>
</Root>
</Loggers>
</Configuration>
Command line (CLI) parameters¶
There are a number of CLI parameters you can pass to the call in your graylogctl script:
-h,--help: Show help message-f CONFIGFILE,--configfile CONFIGFILE: Use configuration fileCONFIGFILEfor Graylog; default:/etc/graylog/server/server.conf-d,--debug: Run in debug mode-l,--local: Run in local mode. Automatically invoked if in debug mode. Will not send system statistics, even if enabled and allowed. Only interesting for development and testing purposes.-p PIDFILE,--pidfile PIDFILE: Set the file containing the PID of graylog toPIDFILE; default:/tmp/graylog.pid-np,--no-pid-file: Do not write PID file (overrides-p/--pidfile)--version: Show version of Graylog and exit
Problems with IPv6 vs. IPv4?¶
If your Graylog node refuses to listen on IPv4 addresses and always chooses for example a rest_listen_address like :::9000
you can tell the JVM to prefer the IPv4 stack.
Add the java.net.preferIPv4Stack flag in your graylogctl script or from wherever you are calling the graylog.jar:
~$ sudo -u graylog java -Djava.net.preferIPv4Stack=true -jar graylog.jar
Create a message input and send a first message¶
Log in to the web interface on port 9000 (e.g. http://127.0.0.1:9000) and navigate to System -> Inputs.
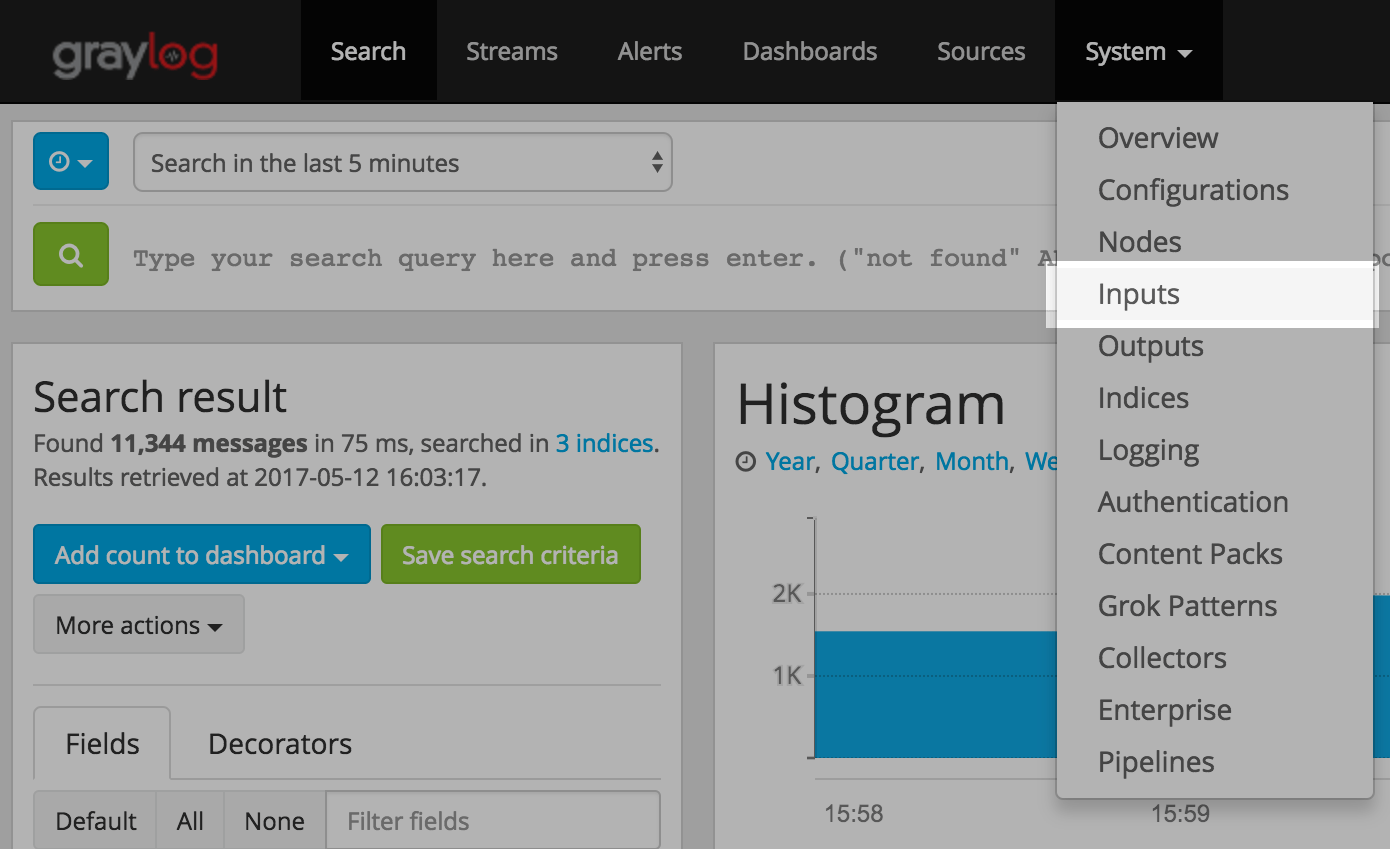
Launch a new Raw/Plaintext UDP input, listening on 127.0.0.1 on port 9099. There’s no need to configure anything else for now.
The list of running inputs on that node should show you your new input right away.
Let’s send a message in:
echo "Hello Graylog, let's be friends." | nc -w 1 -u 127.0.0.1 9099
This has sent a short string to the raw UDP input you just opened. Now search for friends using the search bar on the top and you should already see the message you just sent in. Click on it in the table and see it in detail:
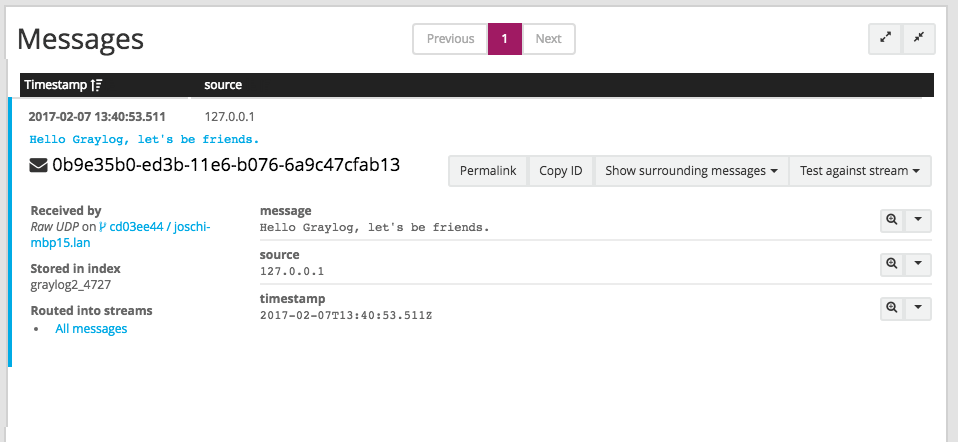
You have just sent your first message to Graylog! Why not spawn a syslog input and point some of your servers to it? You could also create some user accounts for your colleagues.